






The requirement
A leading energy company approached Syngene to develop an artificial intelligence (AI) approach for analyzing hydrocarbon mixtures.The solution would have to identify the various components in a mixture of hydrocarbons while overcoming the limitations associated with traditional analytical methods,including predicting their physical properties.
The challenge
Hydrocarbons are the principal components of fuels and are analyzed using gas or liquid chromatography‑mass spectrometry (GC-MS, LC-MS). Though these techniques are effectively used for separating, detecting, and identifying impurities in mixtures, applying them to long-chain hydrocarbons is not straightforward.
- Characterizing impurities present in a sample is challenging in the absence of a reference mass spectral library. A reference library is essential for identifying each component present in a mixture. The absence of a reference library for long‑chain hydrocarbons impedes the prediction of relevant properties for these mixtures.
- Multiple experiments are required to analyze and characterize the samples, which is a cumbersome process.

The solution
To address these challenges, Syngene scientists designed a workflow that uses a combination of cheminformatics and deep learning to:
- Predict the mass spectrum of long-chain hydrocarbons
- Create a reference library for mass spectra analysis
- Predict probable impurities generated during synthesis from mass spectra data of the sample
- Predict physical properties of the compounds, such as temperature-dependent viscosity and density
Approach details
Traditional machine learning (ML) tools are not very effective in predicting the properties of hydrocarbon mixtures. This is compounded by the fact that the components differ by a few carbons or side-chain positions. Most fingerprint-based representations of compounds cannot decode these minor differences.
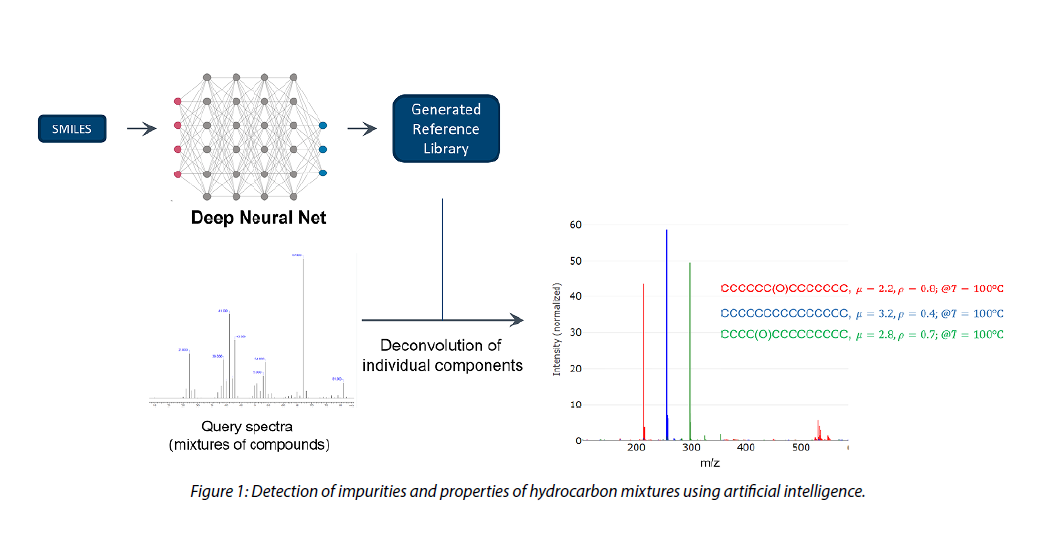
Syngene developed a graph embedding method that uses precursor types and experimental conditions like ionization energy to train a deep learning model. With this model, the client can predict the mass spectrum of long-chain hydrocarbons with reasonable accuracy (Figure 1).
The model was used to create a reference mass spectra library for long-chain hydrocarbons, which scientists could use to deconvolute sample mixtures. This was combined with models that can predict hydrocarbons’ physical properties, including density and viscosity, over a wide temperature range to characterize the sample.
Conclusion
The developed method reliably predicts the physical properties of long-chain hydrocarbon mixtures. This helps scientists identify the compounds in the mixtures and assists them in making decisions related to using these compounds in various product formulations.
Further, the reference spectra library developed using this approach is helping analytical scientists make mass spectrometry more effective for
long-chain hydrocarbons.
This work was enabled by a custom version of Syn.AI TM Syngene’s AI platform for drug discovery.
To know more about our capabilities in artificial intelligence, contact our experts.